deep learning
- neural networks
- training
- CNNs
- gans (2014)
- architectural components
- recent trends
- RNNs
- adversarial attacks
- geometry
neural networks
- basic perceptron update rule
- if output is 0 but should be 1: raise weights on active connections by d
- if output is 1 but should be 0: lower weights on active connections by d
- perceptron convergence thm - if data is linearly separable, perceptron learning algorithm wiil converge
- transfer / activation functions
- sigmoid(z) = $\frac{1}{1+e^{-z}}$
- Binary step
- TanH (always preferred to sigmoid)
- Rectifier = ReLU
- Leaky ReLU - still has some negative slope when <0
- rectifying in electronics converts analog -> digital
- rare to mix and match neuron types
- deep - more than 1 hidden layer
- regression loss = $\frac{1}{2}(y-\hat{y})^2$
- classification loss = $-y log (\hat{y}) - (1-y) log(1-\hat{y})$
- can’t use SSE because not convex here
- multiclass classification loss $=-\sum_j y_j ln \hat{y}_j$
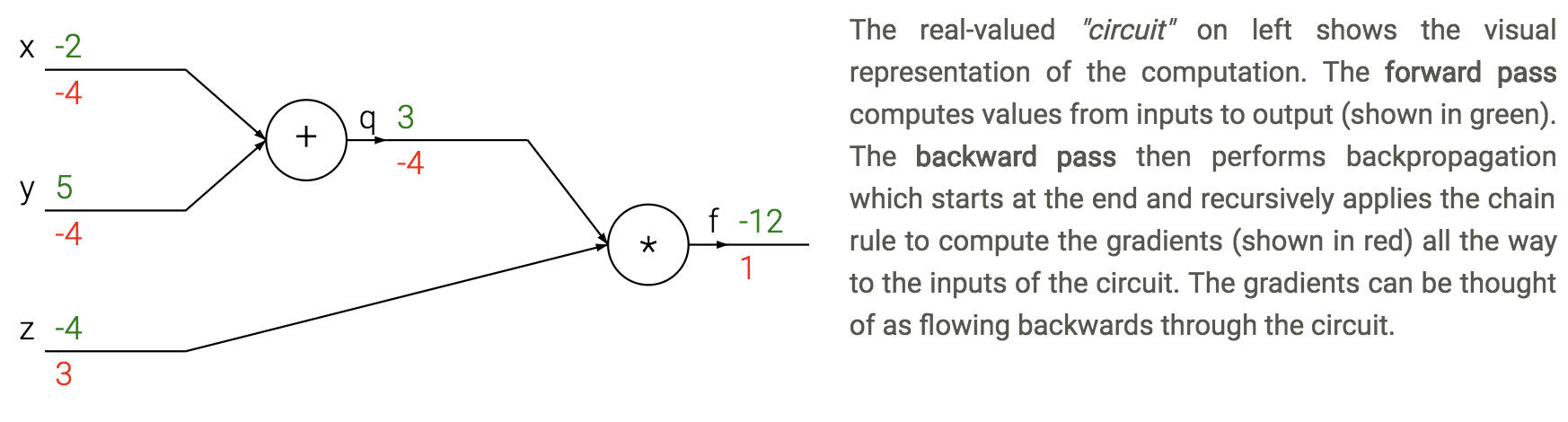
- backpropagation - application of reverse mode automatic differentiation to neural networks’s loss
- apply the chain rule from the end of the program back towards the beginning
- $\frac{dL}{dx_i} = \frac{dL}{dz} \frac{\partial z}{\partial x_i}$
- sum $\frac{dL}{dz}$ if neuron has multiple outputs z
- L is output
- $\frac{\partial z}{\partial x_i}$ is actually a Jacobian (deriv each $z_i$ wrt each $x_i$ - these are vectors)
- each gate usually has some sparsity structure so you don’t compute whole Jacobian
- apply the chain rule from the end of the program back towards the beginning
- pipeline
- initialize weights, and final derivative ($\frac{dL}{dL}=1$)
- for each batch
- run network forward to compute outputs at each step
- compute gradients at each gate with backprop
- update weights with SGD
training
- vanishing gradients problem - neurons in earlier layers learn more slowly than in later layers
- happens with sigmoids
- dead ReLus
- exploding gradients problem - gradients are significantly larger in earlier layers than later layers
- RNNs
- batch normalization - whiten inputs to all neurons (zero mean, variance of 1)
- do this for each input to the next layer
- dropout - randomly zero outputs of p fraction of the neurons during training
- like learning large ensemble of models that share weights
- 2 ways to compensate (pick one)
- at test time multiply all neurons’ outputs by p
- during training divide all neurons’ outputs by p
- softmax - takes vector z and returns vector of the same length
- makes it so output sums to 1 (like probabilities of classes)
CNNs
- kernel here means filter
- convolution G- takes a windowed average of an image F with a filter H where the filter is flipped horizontally and vertically before being applied
- G = H $\ast$ F
- if we do a filter with just a 1 in the middle, we get the exact same image
- you can basically always pad with zeros as long as you keep 1 in middle
- can use these to detect edges with small convolutions
- can do Guassian filters
- convolutions typically sum over all color channels
- 1x1 conv - still convolves over channels
- pooling - usually max - doesn’t pool over depth
- people trying to move away from this - larger strides in conversation layers
- stacking small layers is generally better
- most of memory impact is usually from activations from each layer kept around for backdrop
- visualizations
- layer activations (maybe average over channels)
- visualize the weights (maybe average over channels)v
- feed a bunch of images and keep track of which activate a neuron most
- t-SNE embedding of images
- occluding
- weight matrices have special structure (Toeplitz or block Toeplitz)
- input layer is usually centered (subtract mean over training set)
- usually crop to fixed size (square input)
- receptive field - input region
- stride m - compute only every mth pixel
- downsampling
- max pooling - backprop error back to neuron w/ max value
- average pooling - backprop splits error equally among input neurons
- data augmentation - random rotations, flips, shifts, recolorings
- siamese networks - extract features twice with same net then put layer on top
- ex. find how similar to representations are
- famous cnns
- LeNet (1998)
- first, used on MNIST
- AlexNet (2012)
- landmark (5 conv layers, some pooling/dropout)
- ZFNet (2013)
- fine tuning and deconvnet
- VGGNet (2014)
- 19 layers, all 3x3 conv layers and 2x2 maxpooling
- GoogLeNet (2015)
- lots of parallel elements (called Inception module)
- Msft ResNet (2015)
- very deep - 152 layers
- connections straight from initial layers to end
- only learn “residual” from top to bottom
- Region Based CNNs (R-CNN - 2013, Fast R-CNN - 2015, Faster R-CNN - 2015)
- object detection
- Karpathy Generating image descriptions (2014)
- RNN+CNN
- Spatial transformer networks (2015)
- transformations within the network
- Segnet (2015)
- encoder-decoder network
- Unet (2015)
- Ronneberger - applies to biomedical segmentation
- Pixelnet (2017)
- predicts pixel-level for different tasks with the same architecture
- convolutional layers then 3 FC layers which use outputs from all convolutional layrs together
- Squeezenet
- Yolonet
- Wavenet
- Densenet
- LeNet (1998)
gans (2014)
- original gan paper (2014)
- might not converge
- generative adversarial network
- goal: want G to generate distribution that follows data
- ex. generate good images
- two models
- G - generative
- D - discriminative
- G generates adversarial sample x for D
- G has prior z
- D gives probability p that x comes from data, not G
- like a binary classifier: 1 if from data, 0 from G
- adversarial sample - from G, but tricks D to predicting 1
- training goals
- G wants D(G(z)) = 1
- D wants D(G(z)) = 0
- D(x) = 1
- converge when D(G(z)) = 1/2
- G loss function: $G = argmin_G log(1-D(G(Z))$
- overall $min_g max_D$ log(1-D(G(Z))
- training algorithm
- in the beginning, since G is bad, only train my minimizing G loss function
architectural components
- coordconv - break translation equivariance by passing in i, j coords as extra filters
- deconvolution = transposed convolution = fractionally-strided convolution - like upsampling
- attention
- attention ovw: https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
- vector of importance weights: in order to predict or infer one element, such as a pixel in an image or a word in a sentence, we estimate using the attention vector how strongly it is correlated with (or “attends to” as you may have read in many papers) other elements and take the sum of their values weighted by the attention vector as the approximation of the target.
- attention born to solve problem of going from arbitrary length -> fixed length encoding -> arbitrary length output
recent trends
- architecture search: learning to learn
- optimal brain damage - starts with fully connected and weeds out connections (Lecun)
- tiling - train networks on the error of previous networks
RNNs
- feedforward NNs have no memory so we introduce recurrent NNs
- able to have memory
- could theoretically unfold the network and train with backprop
- truncated - limit number of times you unfold
- $state_{new} = f(state_{old},input_t)$
- ex. $h_t = tanh(W h_{t-1}+W_2 x_t)$
- train with backpropagation through time (unfold through time)
- truncated backprop through time - only run every k time steps
- error gradients vanish exponentially quickly with time lag
LSTMs
- have gates for forgetting, input, output
- easy to let hidden state flow through time, unchanged
- gate $\sigma$ - pointwise multiplication
- multiply by 0 - let nothing through
- multiply by 1 - let everything through
- forget gate - conditionally discard previously remembered info
- input gate - conditionally remember new info
- output gate - conditionally output a relevant part of memory
- GRUs - similar, merge input / forget units into a single update unit \vert
adversarial attacks
- adversarial attack - designing an input to get the wrong result from the model
- targeted - try to get specific wrong class
- fast gradient step method - keep adding gradient to maximize noise (limit amplitude of pixel’s channel to stay imperceptible)
geometry
- transformers: https://arxiv.org/pdf/1706.03762.pdf
- spatial transformers: https://papers.nips.cc/paper/5854-spatial-transformer-networks.pdf
- http://colah.github.io/posts/2014-03-NN-Manifolds-Topology/