info retrieval
- introduction
- related fields
- web crawler
- inverted index
- query processing
- user
- ranking model
- latent semantic analysis - removes noise
- probabalistic ranking principle - different approach, ML
- retrieval evaluation
- reading
introduction
- building blocks of search engines
- search (user initiates)
- reccomendations - proactive search engine (program initiates e.g. pandora, netflix)
- information retrieval - activity of obtaining info relevant to an information need from a collection of resources
- information overload - too much information to process
- memex - device which stores records so it can be consulted with exceeding speed and flexibility (search engine)
- IR pieces
- Indexed corpus (static)
- crawler and indexer - gathers the info constantly, takes the whole internet as input and outputs some representation of the document
- web crawler - automatic program that systematically browses web
- document analyzer - knows which section has what -takes in the metadata and outputs the index (condensed), manage content to provide efficient access of web documents
- crawler and indexer - gathers the info constantly, takes the whole internet as input and outputs some representation of the document
- User
- query parser - parses the search terms into managed system representation
- Ranking
- ranking model -takes in the query representation and the indices, sorts according to relevance, outputs the results
- also need nice display
- query logs - record user’s search history
- user modeling - assess user’s satisfaction
- Indexed corpus (static)
- steps
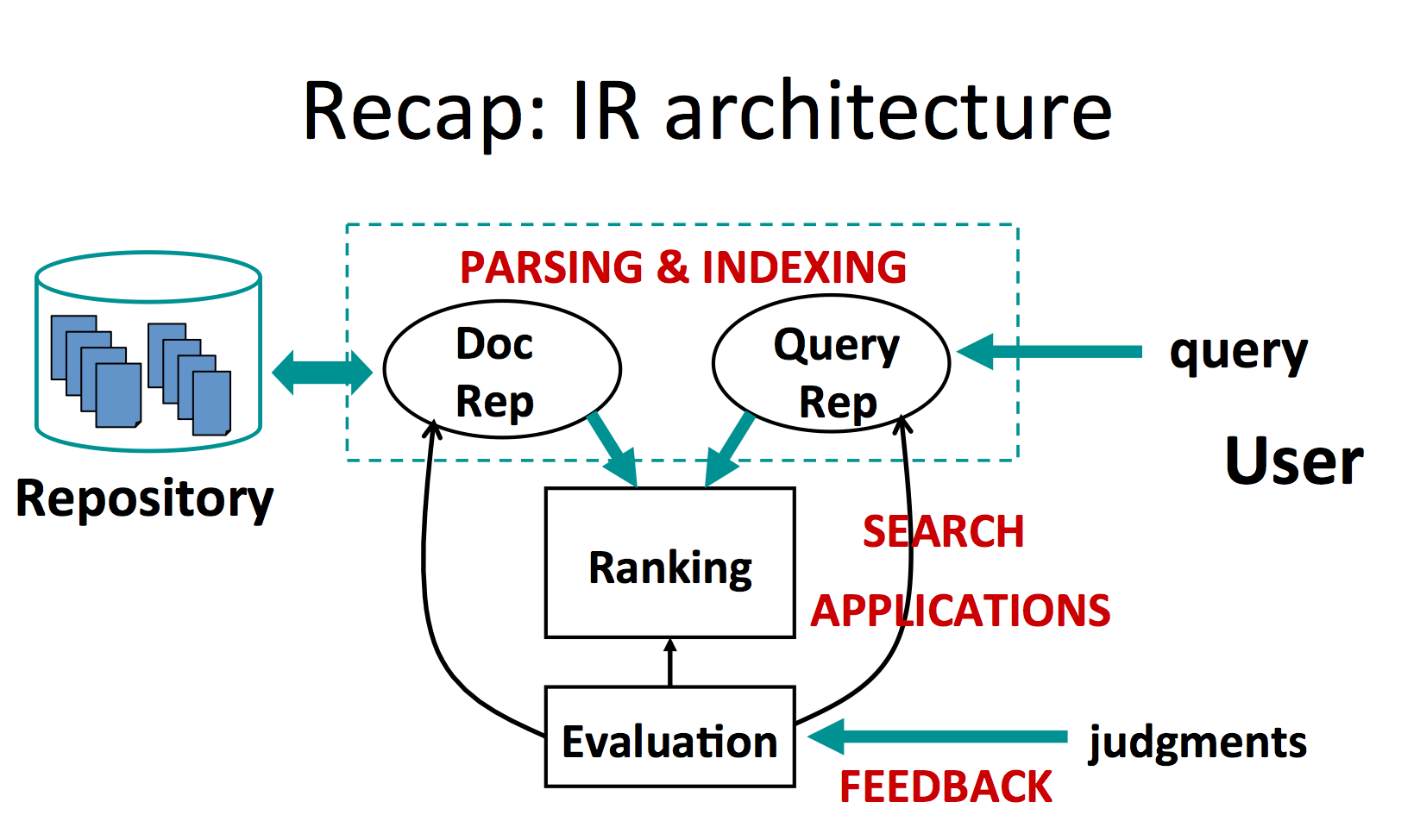
- repository -> document representation
- query -> query representation
- ranking is performed between the 2 representations and given to the user
- evaluation - by users
- information retrieval:
- reccomendation
- question answering
- text mining
- online advertisement
related fields
they are all getting closer, database approximate search and information extraction converts unstructed data to structured:
| database systems | information retrieval |
|---|---|
| structured data | unstructured data |
| semantics are well-defined | semantics are subjective |
| structured query languages (ex. SQL) | simple keyword queries |
| exact retrieval | relevance-drive retrieval |
| emphasis on efficiency | emphasis on effectiveness |
- natural language processing - currently the bottleneck
- deep understainding of language
- cognitive approaches vs. statistical
- small scale problems vs. large
- developing areas
- currently mobile search is big - needs to use less data, everything needs to be more summarized
- interactive retrieval - like a human being, should collaborate
- core concepts
- information need - desire to locate and obtain info to satisfy a need
- query - a designed representation of user’s need
- document - representation of info that could satisfy need
- relevance - relatedness between documents and need, this is vague
- multiple perspectives: topical, semantic, temporal, spatial (ex. gas stations shouldn’t be behind you)
- Yahoo used to have system where you browsed based on structure (browsing), but didn’t have queries (querying)
- better when user doesn’t know keywords, just wants to explore
- push mode - systems push relevant info to users without a query
- pull mode - users pull out info using keywords
web crawler
- web crawler determines upper bound for search engine
- loop over all URL’s (difficult to set its order)
- make sure it’s not visited
- read it and save it as indexed
- setItVisited
- visiting strategy
- breadth first - has to memorize all nodes on previous level
- depth first - explore the web by branch
- focused crawlings - prioritize the new links by predefined strategies
- not all documents are equally important
- prioritize by in-degree
- prioritize by PageRank - breadth-first in early state then approximate periodically
- prioritize by topical relevance
- estimate the similarity by anchortext or text near anchor
- some websites provide site map for google, disallows certain pages (ex. cnn.com/robots.txt)
- some websites push info to google so it doesn’t need to be crawled (ex. news websites)
- need to revisit to get changed info
- uniform re-visiting (what google does)
- proportional re-visiting (visiting frequency is proportional to page’s update frequency)
- html parsing
- shallow parsing - only keep text between title and p tags
- automatic wrapper generation - regular expression for HTML tags’ combination
- representation
- long string has no semantic meaning
- list of sentences - sentence is just short document (recursive definition)
- list of words
- tokenization - break a stream of text into meaningful units
- several statistical methods
- bag-of-words representation
- we get frequencies, but lose grammar and order
- N-grams (improved)
- continguous sequence of n items from a given sequence of text
- for example, keep pairs of words
- google uses n = 7
- increase vocabulary to V^n
- continguous sequence of n items from a given sequence of text
- full text indexing
- pros: preserves all information, full automatic
- cons: vocab gap: car vs. cars, very large storage
- Zipf’s law - frequency of any word is inversely proportional to its rank in the frequency table
- frequencies decrease linearly
- discrete version of power law
stopwords - we ignore these and get meaningful part
- head words take large portion but are meaningless e.g. the, a, an
- tail words - major portion of dictionary, but rare e.g. dextrosinistral
- risk: we lost structure ex. this is not a good option -> option
- normalization
- convert different forms of a word to normalized form
- USA St. Louis -> Saint Louis
- rule based: delete period, all lower case
- dictionary based: equivalence classes ex. cell phone -> mobile phone
- stemming: ladies -> lady, referring -> refer
- risks: lay -> lie
- solutions
- Porter stemmer - pattern of vowel-consonant sequence
- Krovertz stemmer - morphological rules
- empirically, stemming still hurts performance
- convert different forms of a word to normalized form
- modern search engines don’t do stemming or stopword removal
- more advanced NLP techniques are applied - ex. did you search for a person? location?
inverted index
- simple attempt
- documents have been craweld from web, tokenized/normalized, represented as bag-of-words
- try to match keywords to the documents
- space complexity O(d*v) where d = # docs, v = vocab size
- Zipf’s law: most of space is wasted so we only store the occurred words
- instead of an array, we store a linked list for each doc
- time complexity O(qd_lengthd_num) where q=length of query
- solution
- look-up table for each word, key is word, value is list of documents that contain it
- time-complexity O(q*l) where l is average length of list of documents containing word
- by Zipf’s law, d_length « l
- data structures
- hashtable - modest size (length of dictionary)
- postings - very large - sequential access, contain docId, term freq, term position…
- compression is needed
- sorting-based inverted index construction - map-reduce
- from each doc extract tuples of (termId (key in hashtable), docId, count)
- sort by termId within each doc
- merge sort to get one list sorted by key in hashtable
- compress terms with same termId and put into hashtable
- features
- needs to support approximate search, proximity search, dynamic index update
- dynamic index update
- periodically rebuild the index - acceptable if change is small over time and missing new documents is fine
- auxiliary index
- keep index for new docs in memory
- merge to index when size exceeds threshold
- soln: multiple auxiliary indices on disk, logarithmic merging
- index compression
- save space
- increase cache efficiency
- improve disk-memory transfer rate
- coding theory: E[L] = ∑p(x_l) * l
- instead of storing docId, we store gap between docIDs since they are ordered
- biased distr. gives great compression: frequent words have smaller gaps, infrequent words have large gaps, so the large numbers don’t matter (Zipf’s law)
- variable-length coding: less bits for small (high frequency) integers
- more things put into index
- document structure
- title, abstract, body, bullets, anchor
- entity annotation
- these things are fed to the query
- document structure
query processing
- parse syntax ex. Barack AND Obama, orange OR apple
- same processing as on documents: tokenization -> normalization -> stemming -> stopword removal
- speed-up: start from lowest frequency to highest ones (easy to toss out documents)
- phrase matching “computer science”
- N-grams doesn’t work, could be very long phrase
- soln: generalized postings match
- equality condition check with requirement of position patter between two query terms
- ex. t2.pos-t1.pos (t1 must be immediately before t2 in any matched document)
- proximity query: $\vert t2.pos-t1.pos\vert <= k $
- spelling correction
- pick nearest alternative or pick most common alternative
- proximity between query terms
- edit distance = minimum number of edit operations to transform one string to another
- insert, replace, delete
- speed-up
- fix prefix length
- build character-level inverted index
- consider layout of a keyboard
- phonetic similarity ex. “herman” -> “Hermann”
- solve with phonetic hashing - similar-sounding terms hash to same value
user
- result display
- relevance
- diversity
- navigation - query suggestion, search by example
- list of links has always been there
- search engine reccomendations largely bias the user
- direct answers (advanced I’m feeling lucky)
- ex. 100 cm to inches
- google was using user’s search result feedback
- spammers were abusing this
- social things have privacy concerns
- instant search (refreshes search while you’re typing)
- slightly slows things down
- carrot2 - browsing not querying
- foam tree display, has circles with sizes representing popularity
- has a learning curve
- pubmed - knows something about users, has keyword search and more
- result display
- relevance
- most users only look at top left
- this can be changed with multimedia content
- HCI is attracting more attention now
- mobile search
- multitouch
- less screen space
ranking model
- naive boolean query “obama” AND “healthcare” NOT “news”
- unions, intersects, lists
- often over-constrained or under-constrained
- also doesn’t give you relevance of returned documents
- you can’t actually return all the documents
- instead we have rank docs for the users (top-k retrieval) with different kinds of relevance
- vector space model (uses similarity between query and document)
- how to define similarity measure
- both doc and query represented by concept vectors
- k concepts define high-dimensional space
- element of vector corresponds to concept weight
- concepts should be orthogonal (non-overlapping in meaning)
- could use terms, n-grams, topics, usually bag-of-words
- weights: not all terms are equally important
- TF - term frequency weighting - a frequent term is more important
- normalization: tf(t,d) = 1+log(f), if f(t,d) > 0
- or proportionally: = a+(1-a)*f/max(f)
- normalization: tf(t,d) = 1+log(f), if f(t,d) > 0
- IDF weighting - a term is more discriminative if it occurs only in fewer docs
- IDF(t) = 1+log(N/(d_num(t))) where N = total # docs, d_num(t) = # docs containt t
- total term frequency doesn’t work because words can frequently occur in a subset
- combining TF and IDF - most widely used
- w(t,d) = TF(t,d) * IDF(t)
- TF - term frequency weighting - a frequent term is more important
- similarity measure
- Euclidean distance - penalizes longer docs too much
- cosine similarity - dot product and then normalize
- drawbacks
- assumes term independence
- assume query and doc to be the same
- lack of predictive adequacy
- lots of parameter tuning
- (uses probablity of relevance)
- vocabulary - set of words user can query with
latent semantic analysis - removes noise
- terms aren’t necessarily orthogonal in vectors space model
- synonmys: car vs. automobile
- polysems: fly (action vs. insect)
- independent concept space is preferred (axes could be sports, economics, etc.)
- constructing concept space
- automatic term expansion - cluster words based on thesaurus (WordNet does this)
- word sense disambiguation - use dictionary, word-usage context
- latent semantic analysis
- assumption - there is some underlying structure that is obscurred by randomness of word choice
- random noise contaminates term-document data
- assumption - there is some underlying structure that is obscurred by randomness of word choice
- linear algebra - singular value decomposition
- m x n matrix C with rank r
- decompose into U * D * V^T, where D is an r x r diagonal matrix (like eigenvalues^2)
- U and V are orthogonal matrices
- we put the eigenvalues in D into descending order and only take the first k values to be nonzero
- this is low rank decomposition
- multiply the D’s of different docs get similarity
- eigenvector is new representation of each doc
- principle component analysis - separate things based on direction that maximizes variance
- put query into low-rank space
- LSA can also be used beyond text
- 𝑂(𝑀𝑁2)
probabalistic ranking principle - different approach, ML
- total probablility - use bayes’s rule over a partition
- Hypothesis space H={H_1,…,H_n}, training data E
- $P(H_i\vert E) = P(E\vert H_i)P(H_i)/P(E)$
- prior = P(H_i)
- posterior = $P(H_i\vert E)$
- to pick the most likely hypothesis H*, we drop P(E)
- $P(H_i\vert E) = P(E\vert H_i)P(H_i)$
- losses - rank by descending loss
- a1 = loss(retrieved $\vert $ non-relevant)
- a2 = loss(not retrieved $\vert $ relevant)
- we need to make a relevance measure function
- assume independent relevance, sequential browsing
- most existing ir research has fallen into this line of thinking
- conditional models for $P(R=1\vert Q,D)$
- basic idea - relevance depends on how well a query matches a document
- $P(R=1\vert Q,D)$ = g(Rep(Q,D),t)
- linear regression
- MLE: prediction = $argmax(P(X\vert 0))$
- Bayesian: prediction = $argmax(P(X\vert 0)) P(0)$
ml
- features/attributes for ranking - many things
- use logistic regression to find relevance
- little guidance on feature selection
- this model has completely taken over
generative models for $P(R=1\vert Q,D)$
- compute Odd($R=1\vert Q,D$) using Bayes’ rule
language models
- a model specifying probabilty distributions for different word sequences (generative model)
- too much memory for n-gram, so we use unigrams
- generate text by sampling from discrete distribution
- maximum likelihood estimation (MLE)
- sampling with replacement (like picking marbles from bag) - gives you probability distributions
- when you get a query see which document is more likely to generate the query
- MLE can’t represent unseen words (ex. ipad)
- smoothing
- we want to avoid log zero for these words, but we can’t arbitrarily add to the zero
- instead we add to the zero probabilities and subtract from the probabilities of observed words
- additive smoothing - add a constant delta to the counts of each word
- skews the counts in favor of infrequent terms - all words are treated equally
- absolute discounting - subtract from each nonzero word, distribute among zeros
- reference smoothing - use reference language model to choose what to add
- linear interpolation - subtract a percentage of your probability, distribute among zeros
- dirichlet prior/bayesian - not affected by document length
- effect of smoothing is to get rid of log(0) and to devalue very common words and add weight to infrequent words
- longer documents should borrow less because they see the more uncommon words
- additive smoothing - add a constant delta to the counts of each word
retrieval evaluation
- evaluation criteria
- small things - speed, # docs returned, spelling correction, suggestions
- most important this is satisfying user’s information need
- Cranfield experiments - retreived documents’ relevance is a good proxy of a system’s utility in satisfying user’s information need
- standard benchmark - TREC, hosted by NIST
- elements of evaluation
- document collection
- set of information needs expressible as queries
- relevance judgements - binary relevant, nonrelevant for each query-document pair
- stats
- type 1: false positive - wrongly returneda
- precision - fraction of retrieved documents that are relevant = $p(relevant|retrieved)$ = tp/(tp+fp)
- recall - fraction of relevant documents that are retrieved = $p(retrieved|relevant)$ = tp/(tp+fn)
- they generally trade off
- evaluation is in terms of one query
- unordered evaluation - consider the documents unordered
- calculate the precision P and recall P
- combine them with harmonic mean: F = 1 / (a(1/P)+(1-a)1/R) where a assigns weights, usually pick a=1
- F = 2/(1/P+1/R)
- we do this instead of normal mean because values very close to 0 results in very large denominators
- ranked evaluation w/ binary relevance - consider the ranked results
- precision vs recall has sawtooth shape curve
- recall never decreases
- precision increases if we find relevant doc, decreases if irrelevant 1. eleven-point interpolated (use recall levels 0,.1,.2,…,1.0)
- shouldn’t really use 1.0 - not very meaningful 2. precision@k
- ignore all docs ranked lower than k
- only use relevant docs
- recall@k is problematic because it is hard to know how many docs are relevant 3. MAP - mean average precision - usually best
- considers rank position of each relevant doc
- compute p@k for each relevant doc
- average precision = average of those p@k
- mean average precision = mean over all the queries
- weakness - assumes users are interested in finding many relevant docs, requires many relevance judgements 4. MRR - mean reciprocal rank - only want one relevant doc
- uses: looking for fact, known-item search, navigational queries, query auto completion
- reciprocal rank = 1/k where k is ranking position of 1st relevant document
- mean reciprocal rank = mean over all the queries
- ranked evaluation w/ numerical relevance
- binary relevance is insufficient - highly relevant documents are more useful
- gain is accumulated starting at the top and discounted at lower ranks
- typical discount is 1/log(rank)
- DCG (discounted cumulative gain) - total gain accumulated at a particular rank position p
- DCG_p = rel_1 + sum(i=1 to p) rel_i/log_2(i)
- DCG_p = sum_{i=1 to p}(2^rel_i - 1)/(log_2(1+i)) where rel_i is usually 0 to 4
- this is what is actually used
- emphasize on retrieving highly relevant documents
- different queries have different numbers of relevant docs - have to normalized DCG
- normalized DCG - normalize by the DCG of the ideal ranking
- statistical significance tests - difference could just be because of p values you chose
- p-value - prob of data using null hypothesis, if p < alpha we reject null hypothesis
- sign test
- hypothesis - difference median is zero 2. wilcoxon signed rank test
- hypothesis - data are paired and come from the same population 3. paired t-test
- difference has zero mean value 4. one-tail v. two tail
- lol use two-tail
- kappa statistic - measures accuracy of assesor - P(judges agree)-P(judges agree randomly) / (1-P(judges agree randomly))
- = 0 if they agree by chance
- otherwise 1 or < 0
- P(judges agree randomly) = marginals for yes-yes and no-no
- pooling - hard to annotate all docs - relevance is assessed over a subset of the collection that is formed from the top k documents returned by a number of different IR systems
- p-value - prob of data using null hypothesis, if p < alpha we reject null hypothesis
feedback as model interpolation
- important that we take distance from Q to D not D to Q
- this is because the measure is asymmetric
mp3
- 2^rel - rel can be 0 or 1
- whenever you change stopword removal/stemming, have to rebuild index
- otherwise, you will think they are all important
reading
as we may think
- there are too many published things, hard to keep track
19 web search basics
- client server design
- server communicates with client via a protocal such as http in a markup language such as html
- client - generally a brower - can ignore what it doesn’t understand
- we need to include autoritativeness when thinking about a document’s relevance
- we can view html pages as nodes and hyperlinks as directed edges
- power law: number of web pages w/ in-degree i ~ 1/(i^a)
- bowtie structure: three types of webpages IN -> SCC -> OUT
- spam - would repeat keywords to be included in searches
- there is paid inclusion
- cloaking - different page is shown to crawler than to user
- doorway page - text and metadata to rank highly - then redirects
- SEO (search engine optimizers) - consulting for helping people rank highly
- search engine marketing - how to budget different keywords
- some search engines started out without advertising
- advertising - per click, per view
- competitors can click spam the ads of opponents
- types of queries
- informational - general info
- navigational - specific website
- transactional - buying or downloading
- difficult to get size of index
- shingling - count repeating consecutive sequences
2.2, 20.1, 20.2
- hard to tokenize
2.3, 2.4, 4, 5.2, 5.3
- compression and vocaublary
1.3, 1.4 boolean retrieval
- find lists for each term, then intersect or union or complement
- lists need to be sorted by docId so we can just increment the pointers
- we start with shortest lists and do operations to make things faster
- at any point we only want to look at the smallest possible list
6.2, 6.3, 6.4 vector space model
- tf(t,d) = term frequency of term t in doc d
- uses bag of words - order doesn’t matter, just frequency
- often replaced by wf(t,d) = 1+log(tf(t,d)) else 0 because have way more terms doesn’t make it way more relevant
- also could normalize ntf(t,d) = a + (1-a)*tf(t,d)/tf_max(d) where a is a smoothing term
- idf(t) = inverse document frequency of term t
- collection frequency = total number of occurrences of a term in the collection.
- document frequency df(t) = #docs in that contain term t.
- idf(t) = log(N/df(t)) where N = #docs
- combination weighting scheme: tf_idf(t,d) = tf(t,d)*idf(t) - (tf is actually log)
- document score = sum over terms tf_idf(t,d)
- cosine similarity = doc1*doc2 / ($\vert doc1\vert *\vert doc2\vert $) (this is the dot product)
- we want the highest possible similarity
- euclidean distance penalizes long documents too much
- similarity = cosine similarity of (query,doc)
- only return top k results
- pivoted normalized document length? - generally penalizes long document, but avoids overpenalizing